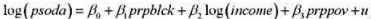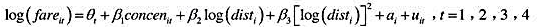题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
利用GPA2.RAW中的数据,可估计出如下方程: 变量sat是SAT的综合分数,hsize是以百人计的学生所在
利用GPA2.RAW中的数据,可估计出如下方程:

变量sat是SAT的综合分数,hsize是以百人计的学生所在高中毕业年级的学生规模,female是一个性别虚拟变量,而black是一个种族虚拟变量(黑人取值1,其他人则取值0)。
(i)有很强的证据支持模型中应该包括hsize”吗?从这个方程来看,最优的高中规模是什么?
(ii)保持hsize不变,非黑人女性和非黑人男性之间SAT分数的估计差异是多少?这个估计差异的统计显著性如何?
(iii)非黑人男性和黑人男性之间SAT分数的估计差异是多少?检验其分数没有差异的原假设,备择假设是他们的分数存在差异。
(iv)黑人女性和非黑人女性之间SAT分数的估计差异是多少?为了检验这个差异的统计显著性,你需要怎么做?
 答案
答案
查看答案


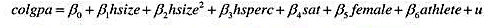
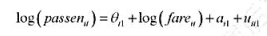
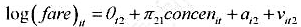
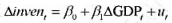 中求出OLS残差,并用
中求出OLS残差,并用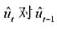 回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?