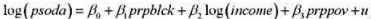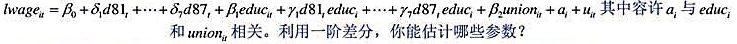题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
利用SLEEP 75.RAW中的数据(也可参见习题3.3) , 我们得到如下估计方程变量sleep是每周晚上睡眠
利用SLEEP 75.RAW中的数据(也可参见习题3.3) , 我们得到如下估计方程变量sleep是每周晚上睡眠
利用SLEEP 75.RAW中的数据(也可参见习题3.3) , 我们得到如下估计方程

变量sleep是每周晚上睡眠的总分钟数, ton work是每周花在工作上的总分钟数, educ和age则以年为单位,而male是一个性别虚拟变量。
(i)所有其他因素不变,有没有男性比女性睡眠更多的证据?这个证据有多强?
(ii)工作与睡眠之问有统计显著的取舍关系吗?所估计的取舍关系是什么样的?
(iii)为了检验年龄在其他因素不变的情况下对睡眠没有影响这个虚拟假设,你还需要另外做什么回归?
 答案
答案
查看答案