

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
在简单线性回归模型y=β0+β1x+u中,假定E(u)≠0。令α0=E(u),证明:这个模型总可以改写
在简单线性回归模型y=β0+β1x+u中,假定E(u)≠0。令α0=E(u),证明:这个模型总可以改写
为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
答案
 更多“在简单线性回归模型y=β0+β1x+u中,假定E(u)≠0。令α0=E(u),证明:这个模型总可以改写”相关的问题
更多“在简单线性回归模型y=β0+β1x+u中,假定E(u)≠0。令α0=E(u),证明:这个模型总可以改写”相关的问题
第1题
考虑简单回归模型
y=β0+β1x+u
令z为x的二值工具变量。运用教材(15.0),证明Ⅳ估计量β1可以写成: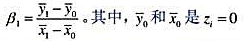 的那部分样本中yi和xi的样本平均值,而
的那部分样本中yi和xi的样本平均值,而 的样本平均值。该估计量称为群组估计量,它是由沃德(Wald,1940)最先提出。
的样本平均值。该估计量称为群组估计量,它是由沃德(Wald,1940)最先提出。
第2题
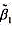 表示通过假定截距为零而得到的β1的估计量。
表示通过假定截距为零而得到的β1的估计量。
第3题
(i)u中包含什么样的因素?它们可能与受教育程度相关吗?
(ii)简单回归分析能够揭示教育对生育率在其他条件不变下的影响吗?请解释。
第4题
利用JTRAIN3.RAW中的数据。
(i)估计简单回归模型re78=β0+β1train+u,并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
(ii)现在使用真实劳动工资的变化cre=re78-re75作为因变量。(由于我们假定1975年之前没有工作培训,所以我们没有必要对train进行差分。也就是说,如果我们定义ctrain=train78-train75,那么,由于train75=0,所以ctrain=train78.)现在,培训的估计影响有多大?讨论它与第(i)部分估计值的比较。
(iii)利用通常的OLS标准误和异方差-稳健标准误求培训效应的95%置信区间,并描述你的结论。
第5题
在简单线性回归模型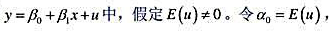 证明:这个模型总可以改写为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
证明:这个模型总可以改写为另一种形式:斜率与原来相同,但截距和误差有所不同,并且新的误差期望值为零。
第7题
(1)如果真实的模型是Yi=β1Xi+μi,但你却拟合了一个带截距项的模型Yi=α0+α1Xi+νi,试评述这一设定误差的后果。
(2)在(1)中,假设真实的模型是带截距项的模型,而你却对过原点的模型进行了普通最小二乘回归。请评述这一模型误设的后果。
第8题
A、Yi=β0+βiXi3+μi
B、Yi=β0+β1(β2Xi)+μi
C、Yi=1+β0(1?Xiβ1)+μi
D、Yi=β0+β1X1i+β2X2i+μi
E、logYi=β0+β1logXi+ui
第10题
(i)变量train是工作培训指标变量。样本中有多少人参与了工作培训项目?一个男人实际参加工作培训最多达几个月?
(ii)将train对unem74,unem75,age,educ,black,hisp和married等几个人口统计和培训前变量做一个线性回归。这些变量在5%的显著性水平上联合显著吗?
(iii)估计第(ii)部分中线性模型的一个概率单位形式。计算所有变量联合显著性的似然比检验。你得到什么结论?
(iv)基于第(ii)部分和第(iii)部分的答案,为解释1978年的失业状况,参与工作培训可视为外生变量吗?请解释。
(v)做unem78对train的简单回归,并以方程形式报告结果。估计参与工作培训项目对1978年失业的概率有何影响?它统计显著吗?
(vi)做unem78对train的概率单位模型。将train的概率单位系数与第(v)部分线性模型中得到的系数相比较有意义吗?
(vii)求出第(v)部分与第(vi)部分的拟合概率。解释它们为什么相同。为了度量工作培训项目的效果和统计显著性,你将采用哪个方法?
(viii)在第(v)部分与第(vi)部分模型中将第(ii)部分中的所有变量作为额外控制变量。现在拟合概率还相同吗?它们之间有何关系?
第11题
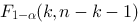 ,如果是一元线性回归,则临界值直接取为
,如果是一元线性回归,则临界值直接取为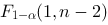 ,这里的参数
,这里的参数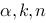 的含义为:
的含义为:A.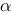 为显著性水平,k为回归模型中自变量的个数,n为样本容量
为显著性水平,k为回归模型中自变量的个数,n为样本容量
B.为显著性水平,k为样本容量,n为回归模型中自变量的个数
C.为显著性水平,k为回归模型中自变量的次数,n为样本容量
D.为显著性水平,k为回归模型中自变量的个数,n为回归模型中自变量的次数























