



 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题用到SMOKE.RAW中的数据。其中, cig pric表示每包香烟的价格(美分) , 而restaur n表示一个二
本题用到SMOKE.RAW中的数据。其中, cig pric表示每包香烟的价格(美分) , 而restaur n表示一个二
本题用到SMOKE.RAW中的数据。
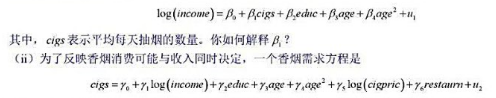
其中, cig pric表示每包香烟的价格(美分) , 而restaur n表示一个二值变量, 并在这个人所定居的州有餐馆抽烟限制时等于1。假定这些变量对个人而言都是外生的,那么你预期y5和y6具有什么样的符号?
(iii)在什么样的条件下第(i)部分的收入方程可识别?
(iv)用OLS估计收入方程并讨论岛的估计值。
(v)估计cigs的约简型。(记住这就要求将cigs对所有外生变量回归。) log(cig pric) 和restaur n在约简型中显著吗?
(vi)现在用2SLS估计收入方程。讨论β1的估计值与OLS估计值的比较。
(vii)你认为香烟价格和餐馆抽烟限制在收入方程中是外生的吗?
 答案
答案
查看答案

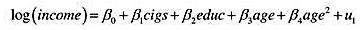
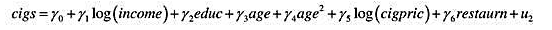
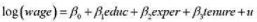
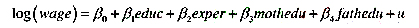
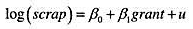
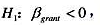 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?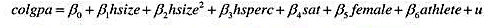
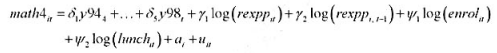
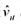 。
。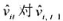 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994~1998年的数据。验证存在很强的正序列相关,并讨论为什么。
























