



 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
利用APPLE.RAW中的数据。这些电话调查数据是为了得到(假想的)“环保”苹果需求。调查者向每个家庭
利用APPLE.RAW中的数据。这些电话调查数据是为了得到(假想的)“环保”苹果需求。调查者向每个家庭都(随机地)介绍了正常苹果和环保苹果的一组价格,并询问他们愿意购买每种苹果的磅数。
(i)对于样本中的660个家庭,有多少家庭报告称在预定价格上不愿意购买环保苹果?
(ii)变量ecolbs看上去在严格正值上具有连续分布吗?你的回答对ecolbs托宾模型的适当性有何含义?
(iii)以ecoprc、regprc、famic和hhsize作为解释变量,估计一个托宾模型。哪些变量在1%的水平上显著。
(iv)faminc和hhsize联合显著吗?
(v)第(iii)部分中价格变量系数的符号与你的预期一致吗?请解释。
(vi)令β1和β2为ecoprc和regprc的系数,相对一个双侧备择假设,检验假设H0:-β1=β2。报告检验的p值。(如果你的回归软件不能很容易地计算这种检验,你可能还要参考教材4.4节
(vii)对样本中的所有观测求E(ecolbslx)的估计值[见方程(17.25)],称之为ecolbsi。最大和最小拟合值是多少?
(viii)计算ecolbs,和ecolbsi之相关系数的平方。
(ix)现在,利用第(iii)部分中同样的解释变量,估计ecolbs的一个线性模型。为什么OLS估计值比托宾估计值小那么多?从拟合优度来看,托宾模型比线性模型更好吗?
(x)评价如下命题:“由于托宾模型的R,如此之小,所以估计的价格效应可能是不一致的。”
 答案
答案
查看答案

 时取值0。换言之, 在给定价格下, eco buy标志着一个家庭是否购买环保苹果。多大比例的家庭声称要购买环保苹果?
时取值0。换言之, 在给定价格下, eco buy标志着一个家庭是否购买环保苹果。多大比例的家庭声称要购买环保苹果?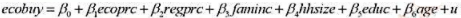
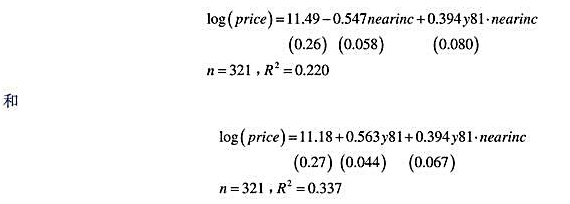
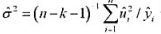 估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?






















