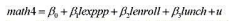题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
本题利用MURDER.RAW中的数据。(i)利用1990年和1993年的数据, 用混合OLS估计方程(iv)做第(ii)部
本题利用MURDER.RAW中的数据。(i)利用1990年和1993年的数据, 用混合OLS估计方程(iv)做第(ii)部
本题利用MURDER.RAW中的数据。
(i)利用1990年和1993年的数据, 用混合OLS估计方程

(iv)做第(ii)部分中的同样回归,但求异方差-稳健的t统计量。结果如何?
(v)你认为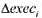 的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
的哪个1统计量更值得信赖, 是通常的!统计量还是异方差-稳健的1统计量?为什么?
 答案
答案
查看答案





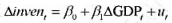 中求出OLS残差,并用
中求出OLS残差,并用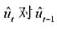 回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?

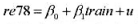 并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?
并用常用格式报告结论。基于这个回归,1976年和1977年的工作培训看上去对1978年的真实劳动工资有正的影响吗?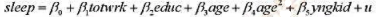
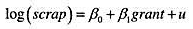
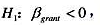 它在5%的显著性水平上统计显著吗?
它在5%的显著性水平上统计显著吗?