

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
在两样本率比较的X2检验中,备择假设(H1)的正确表达应为()。
A.π1≠π2
B.π1 =π2
C.P1 ≠ P2
D.P1 = P2
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.π1≠π2
B.π1 =π2
C.P1 ≠ P2
D.P1 = P2
答案
 更多“在两样本率比较的X2检验中,备择假设(H1)的正确表达应为()。”相关的问题
更多“在两样本率比较的X2检验中,备择假设(H1)的正确表达应为()。”相关的问题
第5题
利用401KSUBS.RAW中的数据。
(i)计算样本中netta的平均值、标准差、最小值和最大值。
(ii)检验假设:平均netta不会因为401(k)资格状况而有所不同,使用双侧备择假设。估计差异的美元数量是多少?
(iii)根据第7章的计算机练习C7的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e401k作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv)在第(ii)部分估计的模型中,增加交互项e401k(age-41)和e401k-(age-41)2。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi)现在,从模型中去掉交互项,但定义5个家庭规模虚拟变量:fsizel,fsize2,fsize3,fsize4和fsize5。对有5个或5个以上成员的家庭,fsize5等于1。在第(ii)部分估计的模型中,增加家庭规模虚拟变量,记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii)现在,针对模型
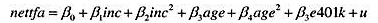
在容许截距不同的情况下,做5个家庭规模类别的邹至庄检验。约束残差平方和SSR,从第(iv)部分得到,因为那里回归假定了相同斜率。无约束残差平方和 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
第7题
A.两文结果有矛盾
B.两文结果完全相同
C.甲文结果更可信
D.乙文结果更可信
第9题
利用PNTSPRD.RAW中的数据。
(i)变量favwin是一个二值变量,在拉斯维加斯所押的球队胜出了预定的分数差时取值1。估计所押球队获胜概率的线性概率模型为
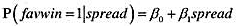
如果分数差包括了所有相关的信息,那我们预期β0=0.5。请解释。
(ii)用OLS估计第(i)部分的模型。相对于双侧备择假设检验H0:β0=0.5。同时使用通常的标准误和异方差一稳健的标准误。
(iii)spread在统计上显著吗?当spread=10时,被押球队获胜的估计概率是多少?
(iv)现在对P(favwin=Ilspread)估计一个概率单位模型。解释和检验截距项为0的虚拟假设。[提示:注意Φ(0)=0.5。]
(v)利用概率单位模型估计当spread=10时被押球队获胜的概率。并与第(iii)部分的LPM估计值相比较。
(vi)在概率单位模型中增加变量fuvhome、fav25和und25,并用似然比检验来检验这些变量的联合显著性。(x2分布中的自由度是多少?)解释这个结果,注意分数差是否包括了赛前可观测到的全部信息这个问题。
第10题
利用INTQRT.RAW中的数据。
在教材例18.7中,我们估计了六月期国库券持有期收益率的一个误差修正模型,其中三月期国库券持有期收益率的一阶滞后为解释变量。我们假定在方程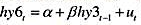 中的协整参数为1。现在,添加Δhy3t-1的先导变化Δhy3t、同期变化Δhy3t-1和滞后变化Δhy3t-2。即估计方程
中的协整参数为1。现在,添加Δhy3t-1的先导变化Δhy3t、同期变化Δhy3t-1和滞后变化Δhy3t-2。即估计方程
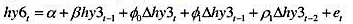
并用方程形式报告结果。相对于双侧备择假设,检验H:β=1.假定方程中已经有了足够多的先导和滞后,使得{hy3t-1}在这个方程中是严格外生的,我们不必担心序列相关。
(ii)在教材(18.39)中的误差修正模型中,添加{hy3t-1}和{hy6t-2-hy3t-3}。这两项是联合显著的吗?你认为怎样才是适当的误差修正模型?
第11题
,H1:μ=μ1>0.5,取单边检验拒绝域W=(x1,x2,...,xn):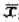 ≥C},其中
≥C},其中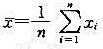 为样本均值,在α=0.05,μ1=0.65时,为使犯第二类错误的概率β不超过0.05,样本容量n至少应取多少?
为样本均值,在α=0.05,μ1=0.65时,为使犯第二类错误的概率β不超过0.05,样本容量n至少应取多少?























