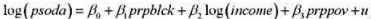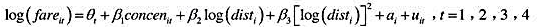题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[主观题]
利用BWGHT.RAW中的数据,可估计出如下方程: 变量定义和教材例4.9中一样,但我们增加了两个虚拟
利用BWGHT.RAW中的数据,可估计出如下方程:

变量定义和教材例4.9中一样,但我们增加了两个虚拟变量:一个虚拟变量表明孩子是不是男孩,另一个虚拟变量则表明这个孩子是不是白人。
(i)在第一个方程中,解释变量cigs的系数。具体而言,每天多抽10根烟对婴儿出生体重有何影响?
(ii)在第一个方程中,保持其他因素不变,预计一个白人孩子的出生体重比一个非白人孩子重多少?这个差异是统计显著的吗?
(iii)评价motheduc的估计影响和统计显著性。
(iv)从这些给定信息中,为什么不能计算出检验motheduc和fatheduc联合显著性的F统计量?为了计算这个统计量,还需要做些什么?
 答案
答案
查看答案

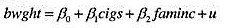

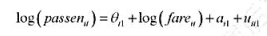
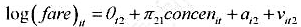
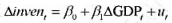 中求出OLS残差,并用
中求出OLS残差,并用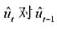 回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?
回归来检验是否存在序列相关。p的估计值是多少?序列相关看起来是多大的问题?