

 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
对两个包含的解释变量个数不同的回归模型进行拟合优度比较时,应比较它们的()。
A.判定系数
B.调整后判定系数
C.标准误差
D.估计标准误差
 答案
答案
查看答案
 请输入或粘贴题目内容
搜题
请输入或粘贴题目内容
搜题
 拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
拍照、语音搜题,请扫码下载APP
题目内容
(请给出正确答案)
A.判定系数
B.调整后判定系数
C.标准误差
D.估计标准误差
答案
 更多“对两个包含的解释变量个数不同的回归模型进行拟合优度比较时,应比较它们的()。”相关的问题
更多“对两个包含的解释变量个数不同的回归模型进行拟合优度比较时,应比较它们的()。”相关的问题
第1题
一个二元线性回归模型的回归结果如下表所示:
方差来源 平方和 自由度
来自残差 17058 32
来自回归 26783 2
来自总离差 43841 34
(1)求样本容量n;(2)求可决系数;
(3)根据以上信息,在给定显著性水平下,可否检验两个解释变量对被解释变量的联合影响是否显著,为什么?
第2题
利用401KSUBS.RAW中的数据。
(i)计算样本中netta的平均值、标准差、最小值和最大值。
(ii)检验假设:平均netta不会因为401(k)资格状况而有所不同,使用双侧备择假设。估计差异的美元数量是多少?
(iii)根据第7章的计算机练习C7的第(ii)部分,e401k在一个简单回归模型中显然不是外生的,起码它随着收入和年龄而变化。以收入、年龄和e401k作为解释变量估计nettfa的一个多元线性回归模型。收入和年龄应该以二次函数形式出现。现在,估计401(k)资格的美元效应是多少?
(iv)在第(ii)部分估计的模型中,增加交互项e401k(age-41)和e401k-(age-41)2。注意样本中的平均年龄约为41岁,所以在新模型中,e401k的系数是401(k)资格在平均年龄处的估计效应。哪个交互项显著?
(v)比较第(iii)和(iv)部分的估计值,401(k)资格在41岁处的估计效应差别大吗?请解释。
(vi)现在,从模型中去掉交互项,但定义5个家庭规模虚拟变量:fsizel,fsize2,fsize3,fsize4和fsize5。对有5个或5个以上成员的家庭,fsize5等于1。在第(ii)部分估计的模型中,增加家庭规模虚拟变量,记得选择一个基组。这些家庭虚拟变量在1%的显著性水平上显著吗?
(vii)现在,针对模型
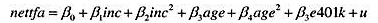
在容许截距不同的情况下,做5个家庭规模类别的邹至庄检验。约束残差平方和SSR,从第(iv)部分得到,因为那里回归假定了相同斜率。无约束残差平方和 其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
其中SSRf是从仅用家庭规模f估计的方程中得到的残差平方和。你应该明白,无约束模型中有30个参数(5个截距和25个斜率),而约束模型中有10个参数(5个截距和5个斜率)。因此,带检验的约束个数是q=20,而且无约束模型的df为9275-30=9245。
第3题
A.一元线性回归预测是回归预测的基础,预测对象只受一个主要因素影响
B.判定一个线性回归方程的拟合程度的优劣称为模型的显著性检验,通常用的检验法是相关系数检验法
C.相关系数等于回归平方和在总平方和中所占的比率,即回归方程所能解释的因变量变异性的百分比,是一元回归模型中用来衡量两个变量之间相关程度的判定指标
D.如果相关系数r=0,表示所有的观测值全部落在回归直线上;如果r=1,则表示自变量与因变量无线性关系
第4题

其中,因为滞后支出变量,第一个可用年份(基年)是1993年。
(i)用混合OLS估计模型,并报告通常的标准误。为使得ai的期望值可以非零,你应该与年度虚拟变量一起包含一个截距项。支出变量的估计效应是什么?求OLS残差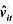 。
。
(ii)lunchit系数的符号在意料之中吗?解释系数的大小。你认为学区的贫穷率对考试通过率有很大的影响吗?
(iii)利用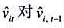 的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
的回归计算AR(1)序列相关的一个检验。你应该在回归中使用1994-1998年的数据。验证存在很强的正序列相关,并讨论为什么。
(iv)现在用固定效应法估计方程。滞后的支出变量仍显著吗?
(v)你为什么认为在固定效应估计中,注册学生人数和午餐项目变量不是联合显著的?
(vi)定义支出的总(或长期)效应为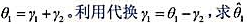 的标准误。
的标准误。
第5题
(i)考虑静态非观测效应模型

其中,enrolit表示学区总注册学生人数,lunchit表示学区中学生有资格享受学校午餐计划的百分数。(因此lunchit是学区贫穷率的一个相当好的度量指标。)证明:若平均每个学生的真实支出提高10%,则math4it约改变β1/10个百分点。
(ii)利用一阶差分估计第(i)部分中的模型。最简单的方法就是在一阶差分方程中包含一个截距项和1994~1998年度虚拟变量。解释支出变量的系数。
(iii)现在,在模型中添加支出变量的一阶滞后,并用一阶差分重新估计。注意你又失去了一年的数据,所以你只能用始于1994年的变化。讨论即期和滞后支出变量的系数和显著性。
(iv)求第(iii)部分中一阶差分回归的异方差-稳健标准误。支出变量的这些标准误与第(iii)部分相比如何?
(v)现在,求对异方差性和序列相关都保持稳健的标准误。这对滞后支出变量的显著性有何影响?
(vi)通过进行一个AR(1)序列相关检验,验证差分误差rit=Δuit含有负序列相关。
(vii)基于充分稳健的联合检验,模型中有必要包含学生注册人数和午餐项目变量吗?
第6题
2部门中平均工资的月增长率(对数的变化),gemp232是232部门中的就业增长率,gmwage是联邦最低工资的增长率,gcpi是(城市)消费者价格指数的增长率。
(i)求gwage232中的一阶自相关。这个序列看起来是弱相关的吗?
(ii)用OLS估计动态模型
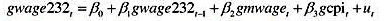
保持上个月的工资增长率和CPI增长率不变,联邦最低工资的提高导致了gwage232t的同期提高吗?请解释。
(iii)在第(ii)部分的方程中添加就业增长率的一阶滞后gemp232t它是统计显著的吗?
(iv)与不包含gwage232t-1和gemp232t-1的模型相比,增加这两个滞后变量显著改变了最低工资变量的估计效应了吗?
(v)做gnwaget对gwage232t-1和gep232t-1的回归,并报告R2。评论这个R值如何有助于你对第(iv)部分的回答。
第7题
利用BWGHT2.RAW中的数据。
(i)估计模型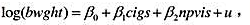 并按照通常的方式报告估计方程,包括样本容量和R²。斜率系数的符号与你的预期一致吗?请加以解释。
并按照通常的方式报告估计方程,包括样本容量和R²。斜率系数的符号与你的预期一致吗?请加以解释。
(ii)如果npvis增加一个样本标准差,对出生重量(bwght)有什么影响?
(iii)现在做log(bwght)对cigs的简单回归,并将斜率系数与第(i)部分中得到的估计值进行比较。估计出来吸烟的效应是否和第(i)部分的有明显差别?
(iv)找出cigs和npvis之间的系数,并用它来解释简单回归和多元回归下β1估计值的相似性。
(v)向第(i)部分的回归方程中加入变量mage,meduc,fage和feduc。出生体重[更确切地说是log(bwght)]是一个容易解释的变量吗?
第8题
使用SMOKE.RAW中的数据。
(i)变量cigs是平均每天抽烟的数量。样本中有多少人根本就不抽烟?有多大比例的人声称每天抽20支?你为什么认为抽20支香烟的人会有所堆积?
(ii)给定你对第(i)部分的回答,cigs看起来具有条件泊松分布吗?
(iii)用log(cigpric)、log(income)、white、educ、age和age2作为解释变量,估计cigs的一个泊松回归模型。估计的价格和收入弹性是多少?
(iv)利用极大似然标准误,价格和收入变量在5%的水平上统计显著吗?
(v)求方程(17.35)后面介绍的σ2估计值。σ是多少?你应该如何调整第(iv)部分中的标准误?
(vi)利用第(v)部分中调整后的标准误,价格和收入弹性现在统计显著异于零吗?请解释。
(vii)利用更稳健的标准误,教育和年龄变量显著吗?你如何解释educ的系数?
(viii)求泊松回归模型的拟合值yi。找出最大值和最小值,并讨论指数模型对瘾君子的预测表现。
(ix)利用第(viii)部分的拟合值,求yi和yi之相关系数的平方。
(x)使用第(iii)部分中的解释变量(及相同的函数形式),用OLS估计cigs的一个线性模型。线性模型和指数模型哪个拟合得更好?两者的R都很大吗?
第9题
(i)u中包含什么样的因素?它们可能与受教育程度相关吗?
(ii)简单回归分析能够揭示教育对生育率在其他条件不变下的影响吗?请解释。
第10题
:年龄x1,体重x2(单位:kg),1500m跑用的时间x3(单位:min),静止时心率x4(单位:次/mim),跑步后心率x5(单位:次/min)。对24名38至57岁的志愿者进行了测试,结果如下表。试建立耗氧能力y与诸因素之间的回归模型。
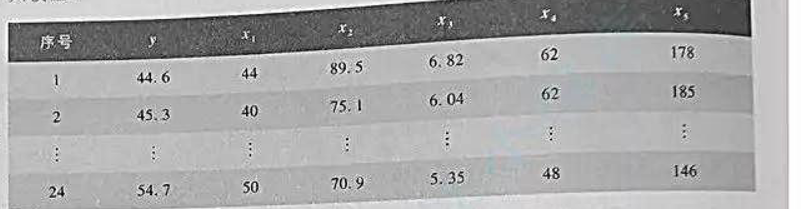
(1)若x1~x5中只许选择1个变量,最好的模型是什么?
(2)若x1~x5中只许选择2个变量,最好的模型是什么?
(3)若不限制变量个数,最好的模型是什么?你选择哪个作为最终模型,为什么?
(4)对最终模型观察残差,有无异常点?若有,剔除后如何?
第11题
(i)变量train是工作培训指标变量。样本中有多少人参与了工作培训项目?一个男人实际参加工作培训最多达几个月?
(ii)将train对unem74,unem75,age,educ,black,hisp和married等几个人口统计和培训前变量做一个线性回归。这些变量在5%的显著性水平上联合显著吗?
(iii)估计第(ii)部分中线性模型的一个概率单位形式。计算所有变量联合显著性的似然比检验。你得到什么结论?
(iv)基于第(ii)部分和第(iii)部分的答案,为解释1978年的失业状况,参与工作培训可视为外生变量吗?请解释。
(v)做unem78对train的简单回归,并以方程形式报告结果。估计参与工作培训项目对1978年失业的概率有何影响?它统计显著吗?
(vi)做unem78对train的概率单位模型。将train的概率单位系数与第(v)部分线性模型中得到的系数相比较有意义吗?
(vii)求出第(v)部分与第(vi)部分的拟合概率。解释它们为什么相同。为了度量工作培训项目的效果和统计显著性,你将采用哪个方法?
(viii)在第(v)部分与第(vi)部分模型中将第(ii)部分中的所有变量作为额外控制变量。现在拟合概率还相同吗?它们之间有何关系?























