



 题目内容
(请给出正确答案)
题目内容
(请给出正确答案)
[单选题]
线性回归中,检验回归模型的F统计量,通常与给定的F临界值做比较,这里与F相比较的临界值取为
线性回归中,检验回归模型的F统计量,通常与给定的F临界值做比较,这里与F相比较的临界值取为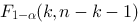 ,如果是一元线性回归,则临界值直接取为
,如果是一元线性回归,则临界值直接取为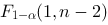 ,这里的参数
,这里的参数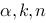 的含义为:
的含义为:
A.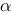 为显著性水平,k为回归模型中自变量的个数,n为样本容量
为显著性水平,k为回归模型中自变量的个数,n为样本容量
B.为显著性水平,k为样本容量,n为回归模型中自变量的个数
C.为显著性水平,k为回归模型中自变量的次数,n为样本容量
D.为显著性水平,k为回归模型中自变量的个数,n为回归模型中自变量的次数
 答案
答案
查看答案

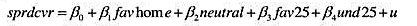
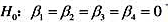 下,模型中不存在异方差性。
下,模型中不存在异方差性。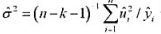 估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?
估计 。数据存在过度散布的证据吗?该如何调整泊松极大似然估计标准误?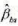 的经济显著性和统计显著性得到什么结论?
的经济显著性和统计显著性得到什么结论?






















